If you read headlines about Artificial Intelligence, you will see two very different types of numbers thrown around.
On one hand, you hear: “Meta spent billions of dollars and months of time to build Llama 3.” On the other hand, you hear: “This new startup runs Llama 3 on your laptop in milliseconds.”
How can something take months and millions of dollars to create, but run instantly on a consumer device?
The answer lies in understanding the two distinct lives of a Machine Learning model: Training and Inference.
To the non-technical observer, “AI” is just “AI.” But to an engineer, these are two completely different worlds. They require different hardware, different mathematics, different teams, and completely different budgets.
If you are planning to deploy AI in the real world, confusing these two phases is the fastest way to burn through your budget.
Part 1: The Non-Technical Analogy (The Student vs. The Professional)
To understand the difference, imagine a law student named Sarah.

Phase 1: Training (The Law School Years)
Sarah spends three years in law school.
- The Input: She reads thousands of case files, textbooks, and legal precedents.
- The Process: She takes practice exams. She gets questions wrong. She gets feedback from professors. She rewrites her understanding of the law based on her mistakes.
- The Effort: This is exhausting. It takes years. It requires expensive tuition (compute power) and massive libraries of books (data).
- The Goal: To rewire her brain to understand patterns in the law.
In Machine Learning terms, this is “Training.” It is the intense, resource-heavy process of teaching the model. The model makes mistakes, calculates the error, and adjusts its internal connections (weights) to get better.
Phase 2: Inference (The Courtroom Appearance)
Now, Sarah is a practicing lawyer. A client walks in and asks, “Is this contract valid?”
- The Input: One specific contract.
- The Process: Sarah reads it. She doesn’t go back to law school for 3 years. She doesn’t re-read every book she owns. She simply accesses the knowledge already stored in her brain and applies it.
- The Effort: It takes 10 minutes.
- The Goal: To provide a correct answer (prediction) based on prior learning.
In Machine Learning terms, this is “Inference.” The learning is done. The model is “frozen.” We are now feeding it live data and asking it to use what it learned to give us a result.
Key Takeaway:
- Training is Learning. (Hard, Slow, Expensive)
- Inference is Doing. (Fast, Cheap, Scalable)
Part 2: The Technical Deep Dive
Now, let’s look at what is actually happening under the hood mathematically. This distinction defines how we architect our cloud infrastructure.
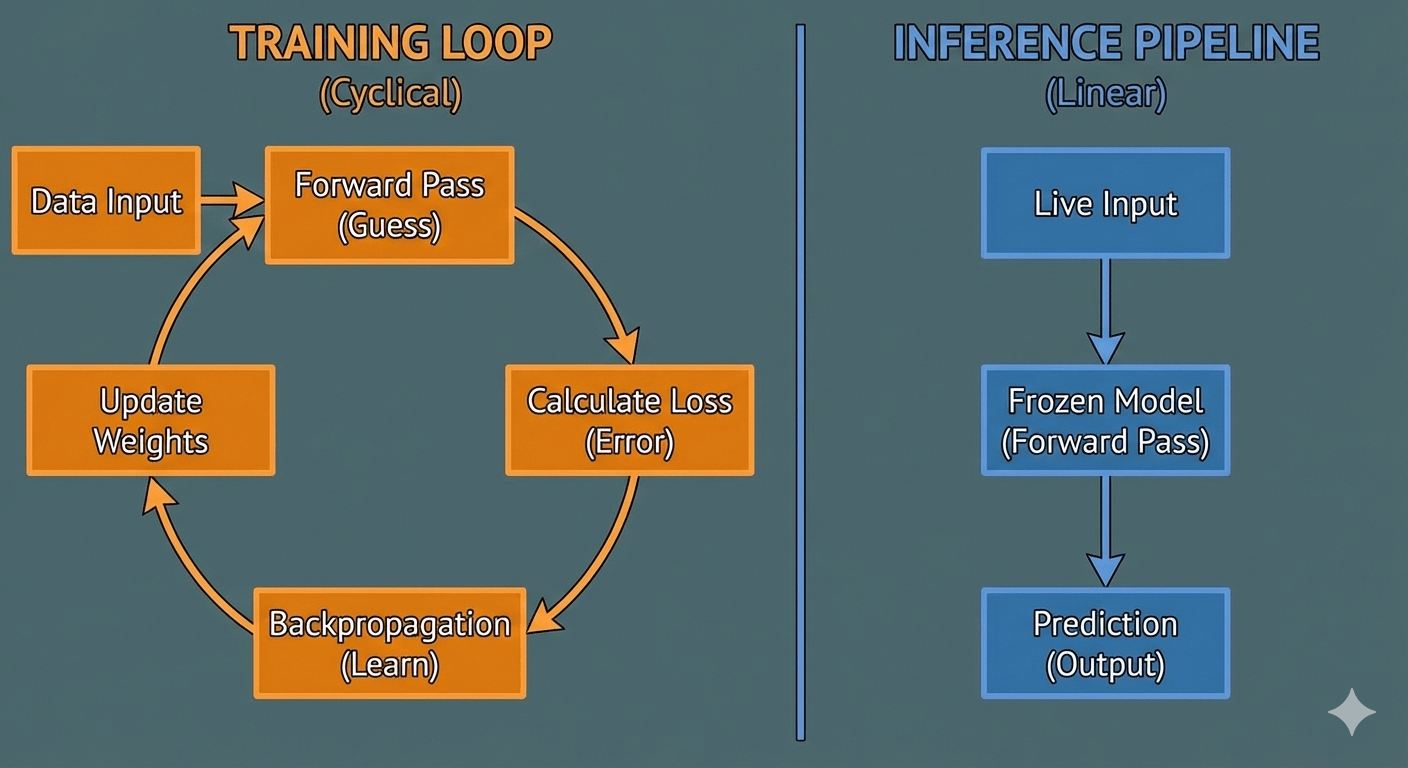
1. Training: The Feedback Loop
Training is an iterative loop of “Guess -> Check -> Correct.”
- Forward Pass: The model takes an input (e.g., an image of a cat) and makes a guess.
- Loss Function: The model compares its guess to the actual label. If it guessed “Dog,” the Loss Function says: “Wrong! Error = 0.8.”
- Backward Pass (Backpropagation): This is the heavy lifting. The algorithm calculates the gradient of the error and goes backwards through the neural network, updating the billions of parameters (weights) slightly so that next time, it is less likely to make that mistake.
- Optimizer: This step actually changes the weights.
Why is it “Very Long” and “Expensive”? Imagine doing this for 1 trillion tokens of text (like ChatGPT). You have to run this loop quadrillions of times. This requires massive clusters of GPUs (like NVIDIA H100s) running at 100% capacity for months.
2. Inference: The One-Way Street
Inference is much simpler. It is purely a Forward Pass.
- Forward Pass: The model takes an input. It multiplies the input by its frozen weights (matrix multiplication).
- Output: It spits out the probability distribution (the prediction).
There is no Loss Function. There is no Backpropagation. The weights are not updated. The model does not “learn” during inference. If ChatGPT gives you a wrong answer today, it doesn’t naturally know it was wrong. It will give the exact same wrong answer tomorrow unless the engineers re-train it.
The “Artifact”
The bridge between these two worlds is the Model Artifact (often a file like model.pt or model.onnx).
- Training produces the artifact.
- Inference loads and reads the artifact.
Part 3: The Economics and Hardware of AI
As a developer or business leader, the distinction between Training and Inference drastically changes what hardware you buy and how you spend your money.
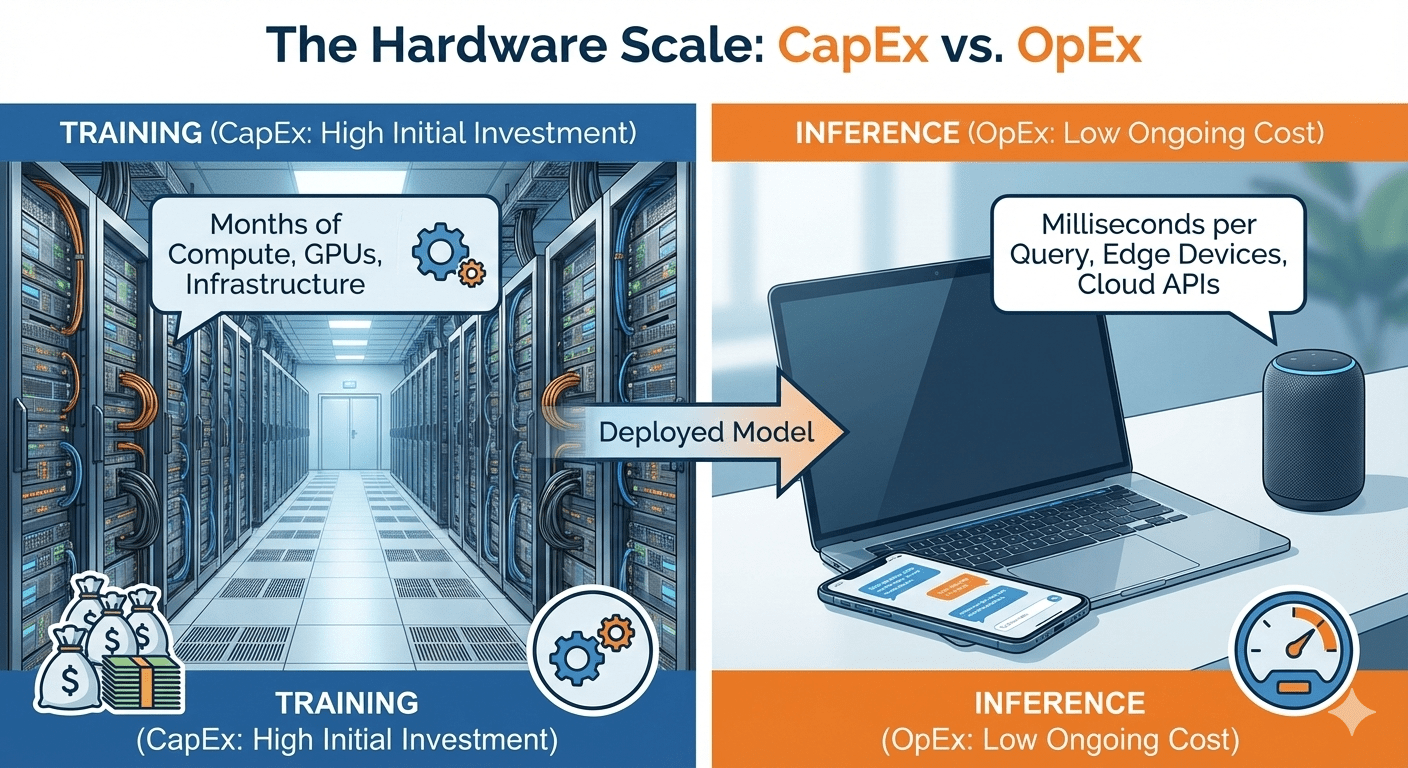
| Feature | Training | Inference |
|---|---|---|
| Compute Need | Massive Parallel Processing. Requires thousands of cores working in sync. | Low Latency. Needs to process one request as fast as possible. |
| Memory (VRAM) | Huge. Must hold the model + gradients + optimizer states + batch data. | Minimal. Only needs to hold the model weights. |
| Hardware | NVIDIA H100 / A100 Clusters. (The heavy machinery). | CPUs, Consumer GPUs (RTX 4090), or Neural Processing Units (NPUs) in phones. |
| Duration | Weeks or Months. | Milliseconds or Seconds. |
| Cost | CapEx (Capital Expenditure). A huge, one-time investment to build the asset. | OpEx (Operating Expenditure). Ongoing cost per user query. |
The “Inference Crisis” Right now, the industry is shifting focus. Training Llama 3 was expensive, but running it for 100 million users every day is astronomically expensive. This is why techniques like Quantization (making the model smaller) and Distillation (teaching a small student model to mimic a large teacher model) are the hottest topics in AI right now. They are all about making Inference cheaper.
Part 4: The Code — Seeing the Difference
Let’s look at this in Python using PyTorch. The code looks similar, but notice the crucial flags that tell the computer: “Stop learning, just work.”
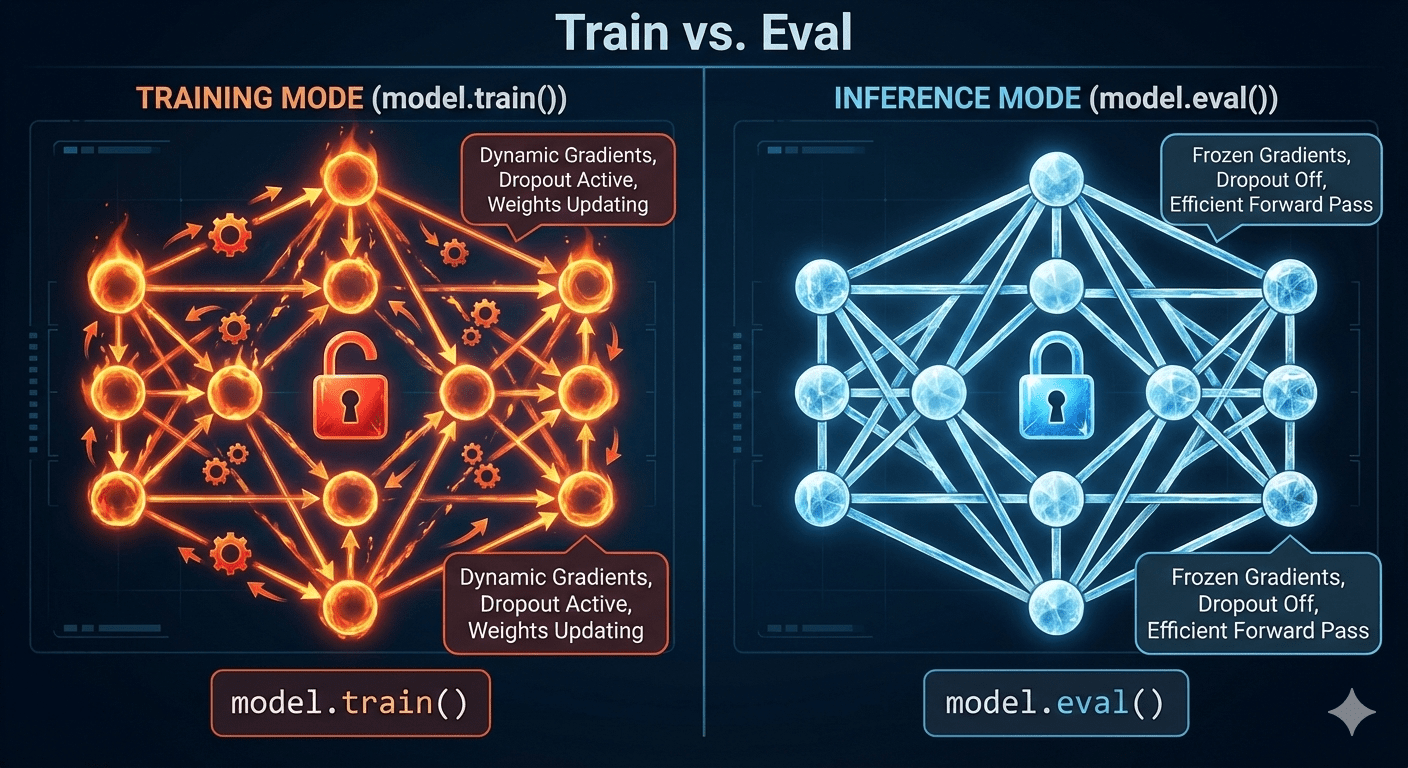
1. The Training Loop (Heavy Lifting)
In this block, we are calculating gradients and updating weights. This consumes memory and power.
import torch
import torch.nn as nn
import torch.optim as optim
# A simple neural network
model = nn.Sequential(nn.Linear(10, 5), nn.ReLU(), nn.Linear(5, 1))
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# Dummy data
data = torch.randn(5, 10) # Input
target = torch.randn(5, 1) # Expected Output
# --- TRAINING MODE ---
model.train() # <--- CRITICAL FLAG: Tells PyTorch "We are learning"
# 1. Forward Pass
prediction = model(data)
# 2. Calculate Error (Loss)
loss = criterion(prediction, target)
# 3. Backward Pass (The Magic)
optimizer.zero_grad() # Clear old gradients
loss.backward() # Calculate new gradients (Backpropagation)
optimizer.step() # Update weights
print(f"Training Loss: {loss.item()}")
2. The Inference Loop (Lightweight)
Now, look at how we run the model in production. We use torch.no_grad() to tell PyTorch: “Do not calculate gradients. Do not store history. Save memory.”
# --- INFERENCE MODE ---
model.eval() # <--- CRITICAL FLAG: Locks layers like Dropout/BatchNormalization
# Context manager to disable gradient calculation
with torch.no_grad():
# We only need the Forward Pass
new_data = torch.randn(1, 10)
prediction = model(new_data)
print(f"Prediction: {prediction.item()}")
Key Code Differences:
model.train()vsmodel.eval(): In training, layers like “Dropout” randomly turn off neurons to prevent memorization. In inference, we want the whole brain working, so we turn Dropout off using.eval().loss.backward(): This exists only in training.torch.no_grad(): This saves massive amounts of memory during inference because we don’t need to remember “how” we got the answer, only “what” the answer is.
Conclusion: The Cycle of Intelligence
Training and Inference are not separate lines; they are a cycle.
- Train a model on historical data.
- Deploy it for Inference in the real world.
- Capture the data from those real-world interactions (and the mistakes the model made).
- Loop back and use that new data to Re-train (or Fine-tune) the model.
This is the Data Flywheel. The companies that master this cycle—running efficient inference to gather data for better training—are the ones winning the AI race.
So, the next time you see a chatbot answer a question instantly, remember: that millisecond of “Inference” was paid for by months of “Training.”
References & Further Reading
If you want to dig deeper into the mechanics of Training and Inference, here are the resources I relied on and highly recommend:
PyTorch Documentation: Training vs. Evaluation Modes
The official documentation explaining exactly what happens to the math when you switch flags.NVIDIA Technical Blog: What is AI Inference?
An excellent breakdown from the hardware perspective, explaining why GPUs are used differently in both phases.Google Machine Learning Crash Course: Training and Test Sets
Google’s standard curriculum for internal engineers, free for everyone.Hugging Face Documentation: Inference for Production
A practical guide on how to take a trained model and actually run it using the Transformers library.