
Introduction: The Taxonomy of Intelligence
In the corridors of modern technology, three acronyms have become the linguistic currency of the decade: AI (Artificial Intelligence), ML (Machine Learning), and DL (Deep Learning).
They are plastered across pitch decks, woven into quarterly earnings calls, and embedded in the source code of the products reshaping our world. Yet, despite their ubiquity, they are frequently—and dangerously—misunderstood.
I often hear them used as synonyms, interchangeable buzzwords meant to signal “advanced technology.” A marketing manager might claim a software is “powered by Deep Learning” when it is running a simple linear regression. A skeptic might dismiss “AI” as a hype bubble without realizing they are using narrow Machine Learning every time they unlock their phone with FaceID.
For professionals—whether you are a developer, a product manager, or a CTO—ambiguity is a liability. If you cannot distinguish between these layers, you risk “using a cannon to kill a mosquito,” or conversely, bringing a knife to a gunfight.
This comprehensive guide is designed to dismantle the confusion. We are going to unpack the hierarchy, the history, and the architectural differences of these three technologies.
To understand where we are going, we must first agree on a map.
The Visual Framework (The Matryoshka Dolls)
The most critical mental model to establish immediately is that these three terms do not sit side-by-side. They are not competing technologies like “iOS vs. Android” or “React vs. Angular.”
They are concentric circles. They are Russian Nesting Dolls (Matryoshka).
- Artificial Intelligence (The Wrapper): The broad, all-encompassing concept of machines acting smartly.
- Machine Learning (The Engine): A subset of AI. The specific technique of teaching computers to learn from data rather than being explicitly programmed.
- Deep Learning (The Fuel Injection): A subset of Machine Learning. A highly specialized technique using multi-layered neural networks to solve complex problems.
The Venn Diagram of Intelligence
Imagine a massive circle labeled Artificial Intelligence. This circle contains everything from the NPCs in Pac-Man (1980) to the logic behind a thermostat.
Inside that circle is a smaller circle labeled Machine Learning. This excludes the Pac-Man ghosts (who followed hard-coded rules) but includes your Netflix recommendation algorithm (which learns from your history).
Inside the ML circle is a tiny, dense dot labeled Deep Learning. This excludes the Netflix algorithm (which is likely a “classic” recommender system) but includes GPT-4 and Midjourney.
If you are “doing Deep Learning,” you are by definition also doing Machine Learning and AI. But if you are “doing AI,” you are not necessarily doing Deep Learning.
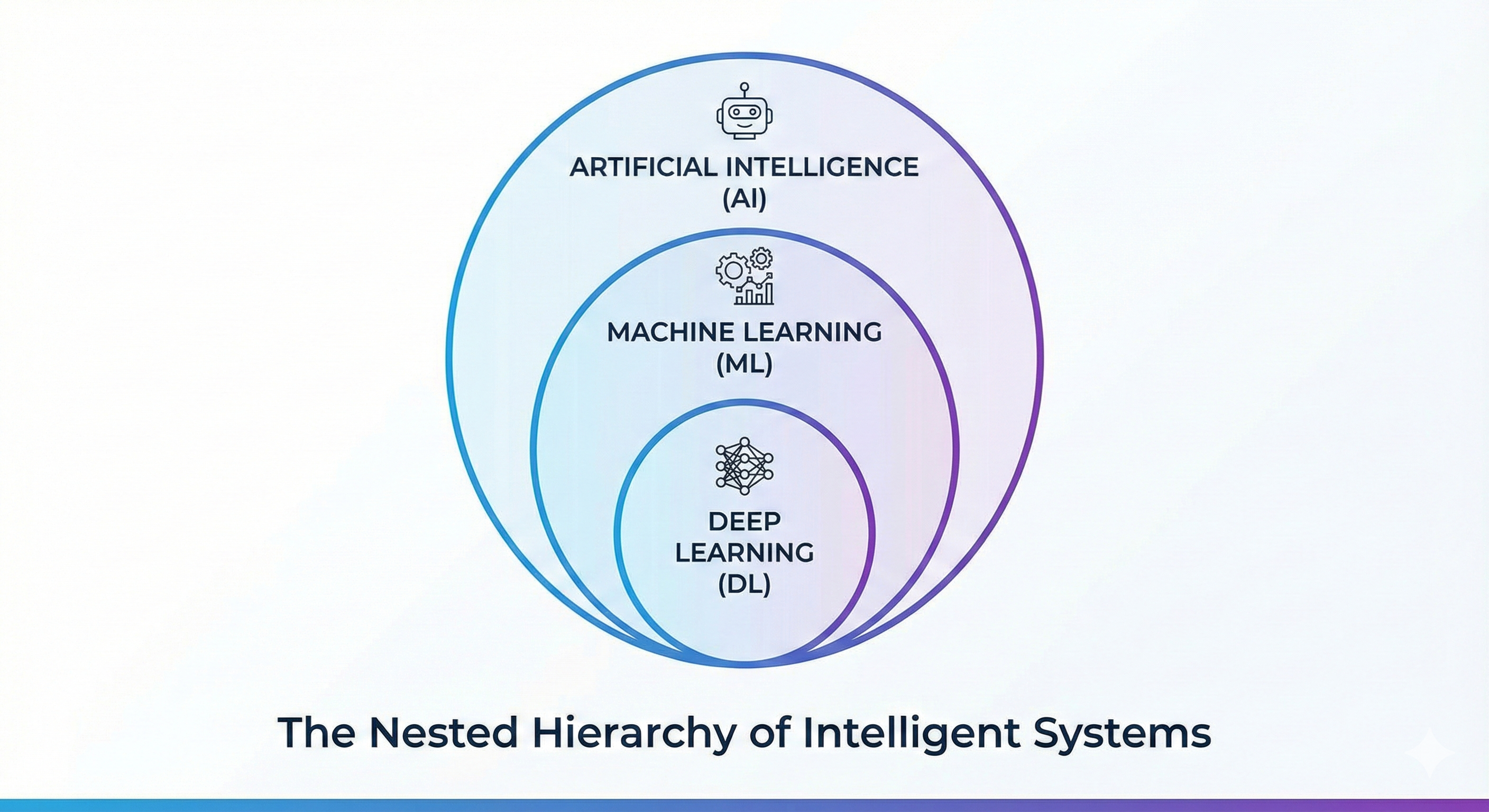
Figure: The nested hierarchy — AI contains ML which contains Deep Learning.
Artificial Intelligence (AI) — The Grand Vision
“The Science of Making Machines Smart”
AI is the oldest term of the three, born in the summer of 1956 at a conference at Dartmouth College. The founding fathers—John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon—proposed a bold conjecture:
“Every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.”
At this level, AI is defined by the outcome, not the method. If a machine solves a problem that typically requires human intelligence, it counts as AI.
The Two Eras of AI
To understand the confusion today, we have to look at the two distinct eras of AI history.
1. Symbolic AI (GOFAI - Good Old-Fashioned AI)
From the 1950s to the late 1980s, AI was dominated by logic. This was the era of Rules, not data.
- The Philosophy: Intelligence is just symbol manipulation. If we can write down the rules of the world, we can code a brain.
- The Mechanism:
IF - THENstatements. - The Example: Deep Blue (1997). When IBM’s Deep Blue defeated chess champion Garry Kasparov, it was a watershed moment. But Deep Blue didn’t “learn” chess. It didn’t practice. It was programmed by Grandmasters with an evaluation function to score positions, and it used massive computing power to calculate millions of moves ahead.
Why it failed: Symbolic AI worked great for Chess and Algebra—closed systems with clear rules. It failed miserably at “easy” human tasks like recognizing a face or understanding a joke. You cannot write an IF-THEN rule for “what a cat looks like.” There are too many variations.
2. The Statistical Turn (The Rise of Modern AI)
In the 1990s, the field realized that hard-coding intelligence was impossible. Instead of teaching the computer what the world looks like, we needed to teach the computer how to look. This marked the transition into the Machine Learning era.
AI Today: ANI vs. AGI
Before we leave the broad “AI” layer, we must address the “Intelligence” part. Currently, all AI in existence is ANI (Artificial Narrow Intelligence).
- ANI: Superhuman at one task (e.g., detecting cancer in X-rays), but completely incompetent at anything else (that same AI cannot play Tic-Tac-Toe).
- AGI (Artificial General Intelligence): The hypothetical AI that possesses flexible, human-level reasoning across any domain. This does not exist yet.
Machine Learning (ML) — The Statistical Revolution
“Programming with Data, Not Rules”
If AI is the vision, Machine Learning is the toolbox that finally made it work.
The term was coined by Arthur Samuel in 1959, who defined it as:
“Field of study that gives computers the ability to learn without being explicitly programmed.”
This distinction—without being explicitly programmed—is the most important concept in modern technology.
The Paradigm Shift
Figure: Machine Learning paradigms — supervised, unsupervised, reinforcement.
- Traditional Programming:
- Input:
Data+Rules - Output:
Answers - Example: You write code that says “If email contains ‘Viagra’, mark as spam.”
- Input:
- Machine Learning:
- Input:
Data+Answers - Output:
Rules - Example: You feed the computer 10,000 spam emails and 10,000 safe emails. The computer analyzes them and writes its own rule: “Emails with ‘Buy Now’ in red text sent at 3 AM are 99% likely to be spam.”
- Input:
The Three Pillars of Machine Learning
Machine Learning is not one algorithm; it is a collection of statistical techniques. They generally fall into three categories based on how the “learning” happens.
1. Supervised Learning (The Teacher)
This is the most common form of ML in business today.
- How it works: You have a “labeled” dataset. You show the model the input (an image of a house) and the correct output (the price of the house). The model tries to guess, you correct it, and it adjusts its math.
- The Algorithms: Linear Regression, Logistic Regression, Decision Trees, Support Vector Machines (SVM).
- Real World Use Case: Credit Scoring. Banks feed historical data of who repaid loans and who defaulted. The model identifies the patterns of a “risky borrower.”
2. Unsupervised Learning (The Explorer)
Here, there are no labels. The data is messy and unstructured. The AI is left alone to find structure in the chaos.
- How it works: “Here is a list of 100,000 customers. I don’t know who they are. Please group them into 5 distinct categories.”
- The Algorithms: K-Means Clustering, Principal Component Analysis (PCA).
- Real World Use Case: Market Segmentation. Discovering that you have a group of “High Spend, Late Night” shoppers that you didn’t know existed.
3. Reinforcement Learning (The Gamer)
This is learning by trial and error.
- How it works: An agent (the AI) is placed in an environment. It takes an action. If the result is good, it gets a “reward” (+1 point). If the result is bad, it gets a “punishment” (-1 point). It plays millions of times until it figures out the optimal strategy.
- Real World Use Case: Robotics (learning to walk) and AlphaGo (the AI that beat the world Go champion).
The Bottleneck: Feature Extraction
Classic Machine Learning had a major limitation. It required human intervention. If you wanted an ML model to recognize a car, a human expert had to define the “features.” You had to write code to say “look for circles (wheels)” and “look for rectangles (windows).” If you messed up the feature definitions, the model failed. This “Feature Extraction” was the ceiling on AI performance… until Deep Learning broke through it.
Deep Learning (DL) — The Neural Revolution
“Mimicking the Biological Brain”
If Machine Learning is the engine, Deep Learning is the rocket fuel. It is the specific subset of Machine Learning that is responsible for the “AI boom” we are living through today (ChatGPT, Midjourney, Self-Driving Cars).
While Deep Learning is mathematically just “Machine Learning on steroids,” functionally, it represents a completely new way of solving problems.
The Architecture: Artificial Neural Networks (ANNs)
Deep Learning is inspired by the biology of the human brain.
Figure: A simplified artificial neural network — inputs, hidden layers, output.
- Biological Brain: Composed of billions of neurons connected by synapses. Signals fire from one neuron to the next, strengthening connections based on experience (learning).
- Artificial Neural Network: Composed of artificial “nodes” (math functions) connected by “weights” (numbers).
The Structure of a Neural Network
- Input Layer: This is where the raw data enters. (e.g., the pixels of an image).
- Hidden Layers: This is the magic “black box” in the middle. These layers perform complex mathematical transformations on the data.
- Output Layer: The final prediction. (e.g., “Probability: 95% Cat”).
Why is it called “Deep”? In the 1980s, neural networks were “Shallow”—they usually had only one hidden layer. They weren’t very powerful. “Deep” Learning simply means the network has many hidden layers (dozens, hundreds, or even thousands). This depth allows the model to learn incredibly complex, hierarchical patterns.
The Killer Feature: Representation Learning
Remember the bottleneck of Classic Machine Learning? Humans had to tell the computer what features to look for (e.g., “look for wheels”). Deep Learning removed the human.
In a Deep Learning model, you just feed in raw pixels.
- Layer 1 learns to identify simple Edges (lines, curves).
- Layer 2 combines those edges to identify Shapes (circles, squares).
- Layer 3 combines shapes to identify Object Parts (eyes, tires, noses).
- Layer 10 combines parts to identify Concepts (Human, Car, Dog).
The system figures out what is important on its own. It extracts its own features. This ability—called Representation Learning—is why Deep Learning dominates in “messy” human domains like Vision (seeing) and NLP (reading/speaking).
The Cost of Depth
Deep Learning is powerful, but it is not free. It comes with three massive costs that distinguish it from classic ML:
- Data Hunger: A classic ML model might work with 5,000 rows of Excel data. A Deep Learning model (like a Transformer) needs trillions of words to learn effectively.
- Computational Cost: You can run Classic ML on a laptop CPU. Deep Learning requires massive clusters of GPUs (Graphics Processing Units) to perform the matrix multiplication required.
- The “Black Box” Problem: In Classic ML (like a Decision Tree), you can trace exactly why the AI made a decision. In Deep Learning, the decision is buried inside billions of floating-point numbers. We often don’t know why the model did what it did.
Generative AI & The Future (The New Frontier)
“From Classification to Creation”
We have now reached the cutting edge. Where do LLMs (Large Language Models) like GPT-4 and Gemini fit into this map?
They are Deep Learning models. Specifically, they use a modern Deep Learning architecture called the Transformer (introduced by Google in 2017).
However, they represent a shift in objective.
Discriminative vs. Generative
- Traditional AI (Discriminative): The goal was to Classify.
- Input: Image -> Output: Label (“Cat”).
- Input: English sentence -> Output: French sentence.
- Modern AI (Generative): The goal is to Create.
- Input: Text Prompt -> Output: A brand new image that never existed before.
- Input: Question -> Output: A unique essay.
Generative AI is not a fourth circle outside of Deep Learning; it is the current application of Deep Learning. It is the result of making neural networks so big and training them on so much data that they begin to “understand” the underlying probability of the entire world.
Summary: The Cheatsheet for Decision Makers
If you are building a product or hiring a team, use this heuristic to decide which “doll” you need:
| Problem Type | Which Tool? | Example |
|---|---|---|
| Logic/Rule-based | Symbolic AI (Code) | A tax calculator. (Don’t use ML for math!) |
| Structured Data | Classic Machine Learning | Predicting house prices from an Excel sheet. |
| Unstructured Data | Deep Learning | Facial recognition, Voice assistants, Translation. |
| Creative/Content | Generative AI (DL) | Writing marketing copy, Generating code, Creating art. |
Conclusion: Respect the Hierarchy
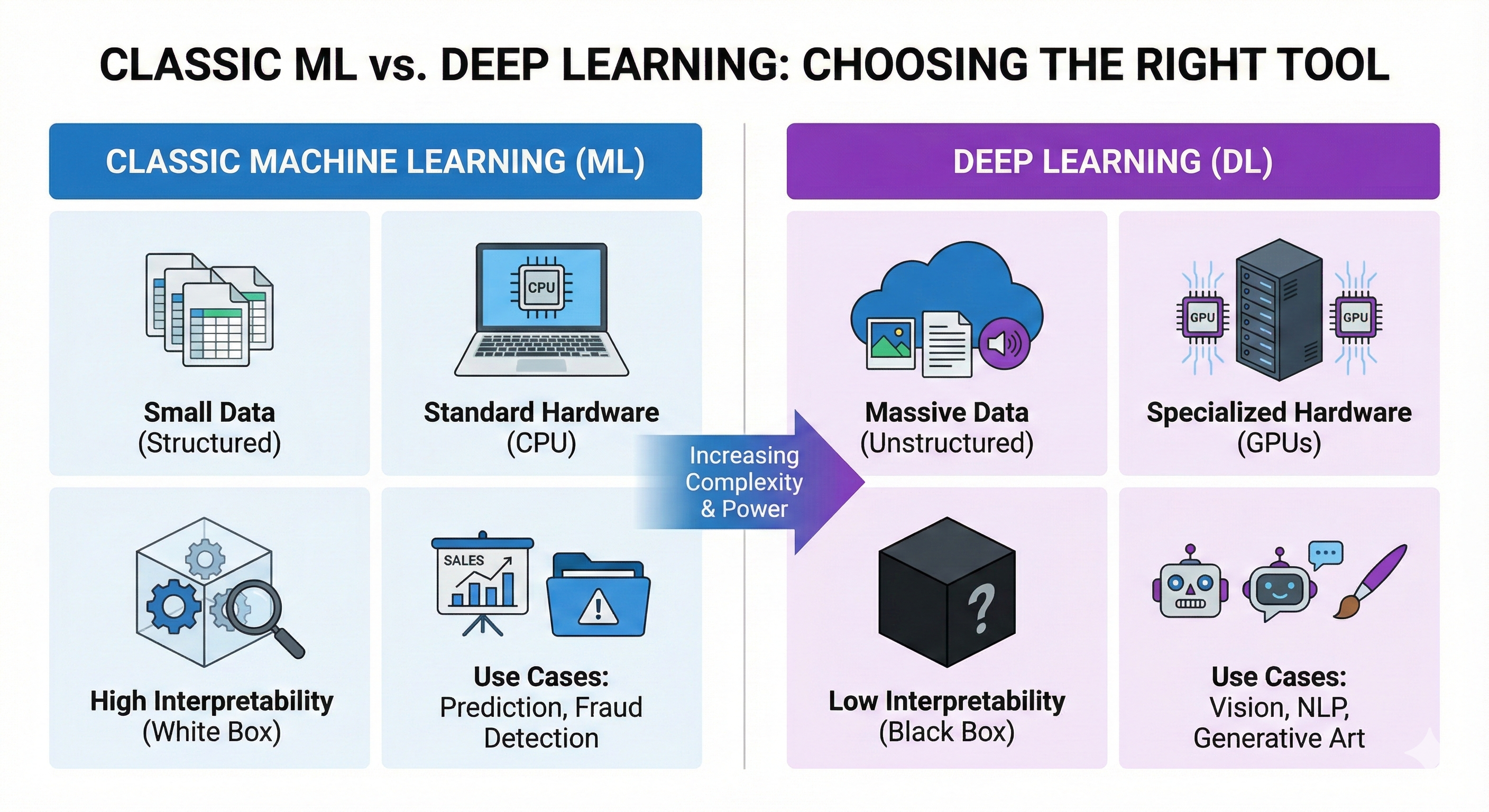
Figure: Comparison — when to choose Classic ML vs Deep Learning.
The next time you see a pitch deck or read a headline, mentally place the technology on the map.
- Is it AI? Yes, almost certainly. That’s an easy label.
- Is it Machine Learning? Does it improve with data? If so, yes.
- Is it Deep Learning? Does it use Neural Networks to learn representations from raw unstructured data?
Understanding this hierarchy protects you from the hype. It helps you realize that “AI” isn’t magic; it’s just math, layered like an onion, solving problems one probability at a time.
The future belongs to those who know which tool to pick up.